关于 OpenKruise
Kruise 是一个有意思的项目,它使用 kubebuilder 框架实现的比原生 Deployment、StatefulSet、CronJob 等更强的 Controller,比如它支持 Partition、Priority、Scatter 等升级策略、InPlace 原地升级、支持 Pause、镜像预热、Broadcast Job 广播任务等,看得出来是针对实际痛点做的,比如 ABJ 就非常适合用于 Node 节点故障巡检和自动化修复场景,Kruise 值得看一看。
Reconcile 核心逻辑
Reconcile 是实现面向终态的核心逻辑,控制器 Reconcile 基本流程如下:
type Reconciler struct {
/*
1. Load the named Resource
2. List all pods, and update the status
3. Clean up old pod according to conditions
4. Check if we're suspended and don't do anything else if we are
5. Get the next reconcile run
6. Run a new pod according to strategy
7. Requeue when we either see a running pod or it's time for the next reconcile run
*/
Reconcile(Request)(Result, error)
}
实现一个面向状态的控制器比传统过程式 CURD 要复杂多了,主要复杂度集中在要正确处理对象多个状态之间的转换,而且可能多个状态会同时并存,比如 Pod 的 Phase = running 和 ReadyCondition = True,同时 reconcile 方法要求是幂等的,任何一种 Event 都会触发 reconcile,执行又线性的,处理状态要考虑哪个状态先处理,哪个后处理的问题。明确定义好对象的状态和状态之间的转换动作是关键,看 Kruise 几个核心的 Resource(CloneSet/AdvancedStatefulset/AdvancedDaemonSet/AdvancedCronJob/AdvancedBroadcastJob) 状态及转换思路如下(每个 Controller 会略有差异,但整体思路不变):
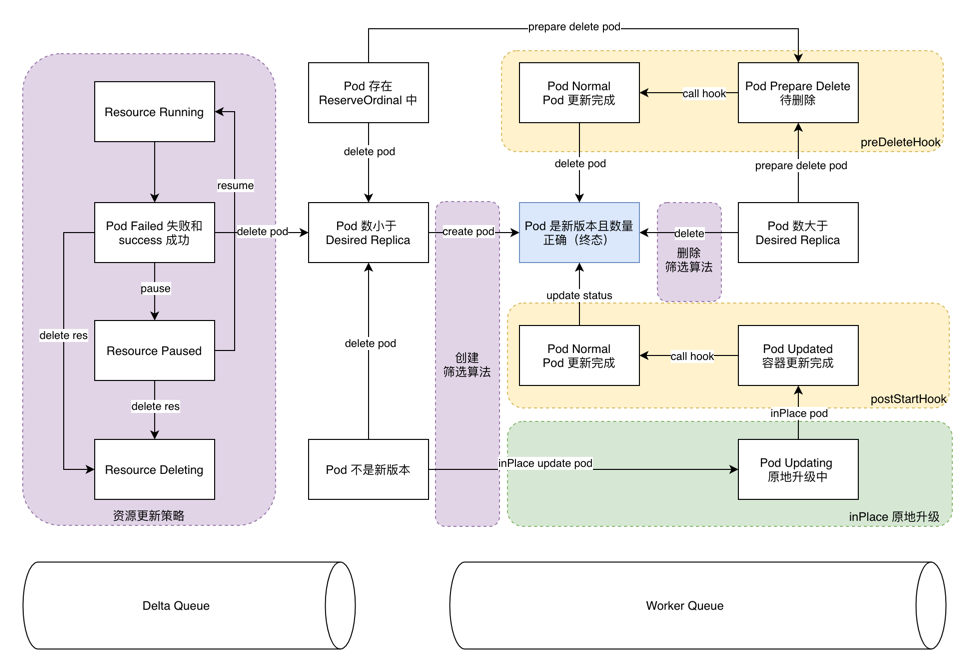
- 正确处理好资源对象状态和 Pod 对象状态,先处理 scale 数量状态再处理 update 版本状态
- 本质围绕着 Pod 对象的终态进行状态编程,根据不同的策略决定了 Pod 的 CURD 操作
- 根据不同的筛选算法决定了 Pod CURD 的 Pod 集和操作顺序
- 任何对 RD 的变更都会触发 Reconcile,设计 RD 的时候要遵循最小化,针对 Pod 的变化而设计
Pod 筛选策略算法
可以看到,reconcile 核心逻辑就是处理好 current 状态和 desired 状态之间的转换,这种转换路径又不同的转换策略算法决定,比如升级的策略、异常启动的策略、删除的策略等,策略确定后,下一步就是确定具体 Pod 的筛选内容和顺序,Kruise 实现了多种筛选策略,比如优先级和离散筛选:
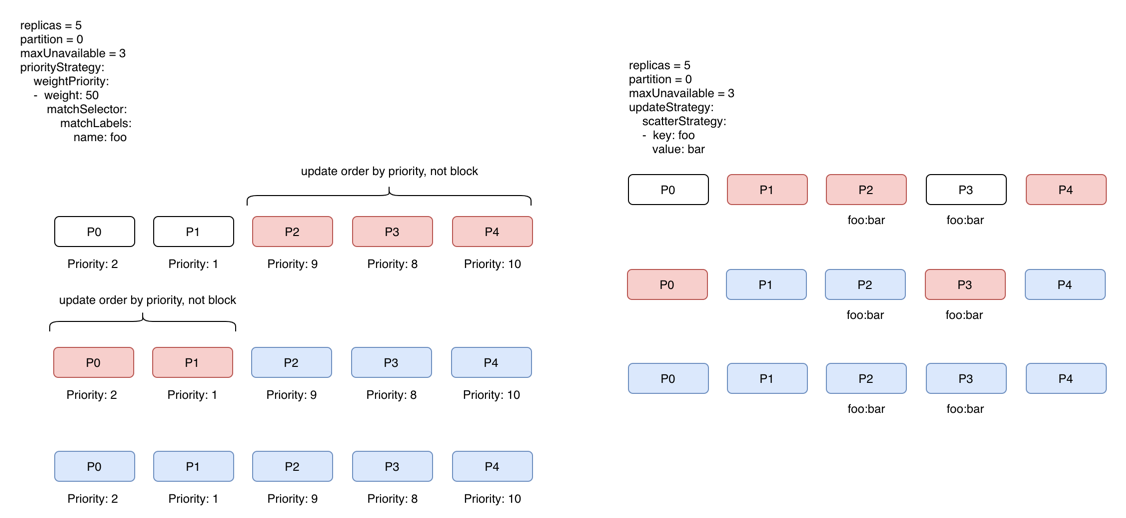
- 按照 Pod 的 label 优先级计算滚动顺序
- 升级虽然按照顺序,但并不是 Pod 等待线性的
关于原地升级
在 K8 的设计中,Pod 升级应该推荐能任意重建,这对无状态服务比较友善,但对有状态 stateful 和 batch 批量任务等场景中,用户更希望 Pod 原地升级,保持 PV 和 IP 不变,比如如下场景:
- 资源受限下无法扩容滚动升级
- Pod 保持 IP 和 PV 不变,能快速升级 Pod
- SideCar Container 升级无需重启宿主 Container
- VPA 扩容 Limit&Request 而无需重启 Pod
in-place 原地升级的诉求早在 2015 年社区就有人提出 issue#9043,讨论激烈,主要诉求:
- Container Image in-place 更新无需重启 Pod
- Container Limit&Request 更新无需重启 Pod
其中 #2 在 2016 年 docker 1.10 支持 live update resource constraints ,社区 2018 年开始着手设计 Pod VPA,目前有望合入 v1.22 版本。
CRD 设计是否大而全
CRD 的任何一个变更都会引起 Reconcile,并通过 selector 来筛选 Pod,如果 CRD 设计大而全的不同对象类型,就要关联多种不同的 Pod,但实际上 Selector 并不能精确匹配 Pod,因此需要抽象出另一个子 CRD,又有子 CRD Controller 来控制,比如 Kruise 在 CronJob 中关联的 BCJ 和 BatchJob 两种类型,CronJob 并没有直接操作 Pod,又比如 Deployment 关联的不同版本的 RS,RS 控制同一个版本的 Pod。可见,大而全的 CRD 通常都拆分 CRD 来完成,否则会非常复杂,从这个角度来说,CRD 原则就应该遵循单一职责设计,控制好上下的组合关系。
能否获取 Pod 其他状态以便设计一些高级运维场景
目前控制器处理的核心逻辑还是 Pod 的数量、版本、运行状态几个变量,对于 Pod 的业务状态靠 kubelet/controller 很难感知,比如 etcd POD 的主从状态,即便是 etcd-operator 的 backup/restore 也是通过定义 spec.EtcdEndpoints 进行的运维操作,并不感知 etcd Pod 业务状态。发现在 Pod 的 Spec 中有 Condition 字段看上去可以描述更多的信息,但得通过 Agent 辅助去刷新以便 Controller 控制器进行编程,因此,通用的状态定义支持的程度非常有限。
我们做 Node 的故障恢复
AdvancedBroadcastJob 非常适合做 Master&Node 节点修复场景,它为每个 Node 节点保证且只有一个 Job Pod 运行,并支持了几种执行策略,但在实际生产过程中做自愈还不太敢用,因为这种 Cluster 级别的修复实际上非常危险,容易引起大的故障,我们希望有浸泡机制和变更后检查机制,这样才不至于引起大面积故障,另外 Job 的执行成功,Pod 为 success 状态结束后也并不代表真正的成功,因为 patch 动作后并不能保证不对现网产生影响。
总结
随着 K8 的使用场景越来越深入,厂家也越做越深,并逐渐构筑自家的竞争力,这也是由实际业务痛点衍生而来,共勉!