摘要
SDN(软件定义网络)使用虚拟设备和转发规则等技术构造了基于物理网络之上的虚拟网络,如 fastly 使用 SDN 技术构建了一个可伸缩的低成本路由器。而在容器生态中,Flannel 为容器网络的一种经典的实现方式,本文探索一下这种实现的基本原理。网上大多数文章还是介绍的 Flannel 第一个 v1 版本 vxlan overlay 实现原理,本文介绍 Flannel vxlan overlay v1 和 v2 两种方式的基本原理及 hostgw、UDP 的实现。
简介
官方定义如下:
Flannel runs a small, single binary agent called flanneld on each host, and is responsible for allocating a subnet lease to each host out of a larger, preconfigured address space. Flannel uses either the Kubernetes API or etcd directly to store the network configuration, the allocated subnets, and any auxiliary data (such as the host's public IP). Packets are forwarded using one of several backend mechanisms including VXLAN and various cloud integrations.
Flannel 是一个极其精简的 Overlay 的容器网络方案,它通常只依赖 kube-api 和每台 Node 运行的 flanneld 进程完成,flanneld 负责为每台 Node 申请一个子网并存储到 kube-api 或 etcd 中,然后通过 vxlan、ipsec、hostgw 等技术实现跨 Node 节点容器互访,同时各个云厂商可以集成各自的实现。实现的核心代码都在 flannel 的 github.com/flannel-io/flannel/backend 目录下:
Flannel vxlan 核心设计和历史
关于 vxlan 的知识网上很多,简单来讲是在 Underlay 网络之上使用 vxlan 网卡把普通 IP 数据封装在 UDP 包中然后穿透 Underlay 层网络从而实现 L2/L3 层的网络包互通,不仅虚拟化使用,K8S 也在应用。
这里网络数据包转发的核心是 RIB 路由表、FDB 转发表、ARP 路由表,即 vxlan 要解决二层 MAC 地址寻址、跨三层 IP 地址寻址的问题,并实现全网高效路由分发和同步,这里先看看 Flannel 的 v1 早期的实现方案。
在最新的 Flannel vxlan 代码 vxlan.go 官方有一段注释说明如下:
// Some design notes and history:
// vxlan encapsulates L2 packets (though Flannel is L3 only so don't expect to be able to send L2 packets across hosts)
// The first versions of vxlan for Flannel registered the Flannel daemon as a handler for both "L2" and "L3" misses
// - When a container sends a packet to a new IP address on the Flannel network (but on a different host) this generates
// an L2 miss (i.e. an ARP lookup)
// - The Flannel daemon knows which Flannel host the packet is destined for so it can supply the VTEP MAC to use.
// This is stored in the ARP table (with a timeout) to avoid constantly looking it up.
// - The packet can then be encapsulated but the host needs to know where to send it. This creates another callout from
// the kernal vxlan code to the Flannel daemon to get the public IP that should be used for that VTEP (this gets called
// an L3 miss). The L2/L3 miss hooks are registered when the vxlan device is created. At the same time a device route
// is created to the whole Flannel network so that non-local traffic is sent over the vxlan device.
//
// In this scheme the scaling of table entries (per host) is:
// - 1 route (for the configured network out the vxlan device)
// - One arp entry for each remote container that this host has recently contacted
// - One FDB entry for each remote host
//
// The second version of Flannel vxlan removed the need for the l3miss callout. When a new remote host is found (either
// during startup or when it's created), Flannel simply adds the required entries so that no further lookup/callout is required.
//
//
// The latest version of the vxlan backend removes the need for the l2miss too, which means that the Flannel deamon is not
// listening for any netlink messages anymore. This improves reliability (no problems with timeouts if
// Flannel crashes or restarts) and simplifies upgrades.
//
// How it works:
// Create the vxlan device but don't register for any l2miss or l3miss messages
// Then, as each remote host is discovered (either on startup or when they are added), do the following
// 1) create routing table entry for the remote subnet. It goes via the vxlan device but also specifies a next hop (of the remote Flannel host).
// 2) Create a static ARP entry for the remote Flannel host IP address (and the VTEP MAC)
// 3) Create an FDB entry with the VTEP MAC and the public IP of the remote Flannel daemon.
//
// In this scheme the scaling of table entries is linear to the number of remote hosts - 1 route, 1 arp entry and 1 FDB entry per host
- Flannel 的 v1 版本,使用 kernal 发出的 l2miss/l3miss 消息 hook 来触发 ARP 和 FDB 流表的定向注入实现。
- Flannel 的 v2 版本,为了更优的可用性、减少流表数量,移除了 l2miss/l3miss 而方式,改为为目的 Node 配置相应的子网,通过配置目的 Node 的子网路由来实现跨 Node 通信。
它的工作模式:
- 创建 vxlan 设备,不再监听任何 l2miss 和 l3miss 事件消息
- 为远端的子网创建路由
- 为远端主机创建静态 ARP 表项
- 创建 FDB 转发表项,包含 VTEP MAC 和远端 Flannel 的 public IP
l2miss 和 l3miss vxlan 实现方案
理论基础
l2miss 和 l3miss vxlan 方案的基础依赖 Kernel 内核的 vxlan DOVE 机制,当数据包无法在 FDB 转发表中找到对应的 MAC 地址转发目的地时 kernel 发出 l2miss 通知事件,当在 ARP 表中找不到对应 IP-MAC 记录时 kernel 发出 l3miss 通知事件。 DOVE 的 kernel patch 如下:
add DOVE extensions for vxlan This patch provides extensions to vxlan for supporting Distributed Overlay Virtual Ethernet (DOVE) networks. The patch includes:
+ a dove flag per vxlan device to enable DOVE extensions
+ ARP reduction, whereby a bridge-connected vxlan tunnel endpoint answers ARP requests from the local bridge on behalf of remote DOVE clients
+ route short-circuiting (aka L3 switching). Known destination IP addresses use the corresponding destination MAC address for switching rather than going to a (possibly remote) router first.
+ netlink notification messages for forwarding table and L3 switching misses
// l2miss - find dest from MAC in FDB
+ f = vxlan_find_mac(vxlan, eth->h_dest);
+ if (f == NULL) {
+ did_rsc = false;
+ dst = vxlan->gaddr;
+ if (!dst && (vxlan->flags & vxlan_F_L2MISS) &&
+ !is_multicast_ether_addr(eth->h_dest))
+ vxlan_fdb_miss(vxlan, eth->h_dest); // 发送 fdb miss 消息
+ }
// l3miss - find MAC from IP in ARP Table
+ n = neigh_lookup(&arp_tbl, &tip, dev);
+
+ if (n) {...}
+ else if (vxlan->flags & vxlan_F_L3MISS)
+ vxlan_ip_miss(dev, tip); // 发送 ip miss 消息
可以看到内核在查询 vxlan_find_mac FDB 转发时未命中则发送 l2miss netlink 通知,在查询 neigh_lookup ARP 表时未命中则发送 l3miss netlink 通知,以便有机会让用户态学习 vm 地址,这就是第一代 Flannel vxlan 的实现基础。
模拟如下:
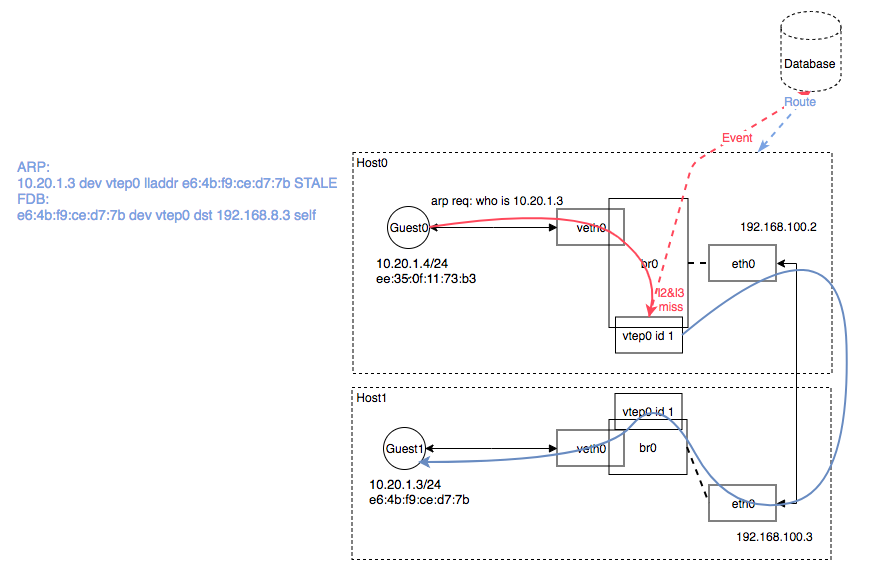
图中 10.20.1.4 与 10.20.1.3 通信流程(不考虑跨子网三层通讯):
- 当 Guest0 第一次发送一个目的地址
10.20.1.3数据包的时候,进行二层转发,查询本地 Guest ARP 表,无记录则发送 ARP 广播who is 10.20.1.3; - vxlan 开启了的本地 ARP 代答 proxy、l2miss、l3miss 功能,当 Host ARP 表无记录时,vxlan 触发 l2miss 事件,ARP 表存储着 IP-MAC-NIC 映射记录,从而实现二层转发;
- l2miss 事件被 Flannel 的 Daemon 进程捕捉到,Daemon 查询后端存储,并代答
10.20.1.3的 MAC 地址为e6:4b:f9:ce:d7:7b并存储 Host ARP 表,因此第一次 ARP 消息是失败的; - 经过步骤3 存入 ARP 表中后,vtep0 命中 ARP 记录后回复 ARP Reply;
- Guest0 收到 ARP Reply 后存 Guest ARP 表,开始发送数据,携带目的
e6:4b:f9:ce:d7:7b地址; - 数据包经过 bridge 时查询 FDB(Forwarding Database entry) 转发表,询问 where
e6:4b:f9:ce:d7:7bsend to? 如未命中记录,发生 l3miss 事件,FDB 表为 2 层交换机的转发表,FDB 存储这 MAC-PORT 的映射关系,用于 MAC数据包从哪个接口出; - Flannel Daemon 捕捉 l3miss 事件,并向 FDB 表中加入目的
e6:4b:f9:ce:d7:7b的数据包发送给对端 Host192.168.100.3; - 此时
e6:4b:f9:ce:d7:7b数据包流向 vtep0 接口,vtep0 开始进行 UDP 封装,填充 VNI 号为 1,并与对端192.168.100.3建立隧道,对端收到 vxlan 包进行拆分,根据 VNI 分发 vtep0 ,拆分后传回 Bridge,Bridge 根据本地 FDB 表找到 dst mac 地址,并转发到对应的 veth 接口上,此时就完成了整个数据包的转发; - 回程流程类似;
下面我们来模拟行 Flannel 的网络实现:
模拟验证
环境:
- 2 台 Centos7.x 机器,2 张物理网卡
- 2 个 Bridge,2 张 vtep 网卡
- 2 个 Namespace,2 对 veth 接口
步骤:
- 创建 Namespace 网络隔离空间模拟 Guest 环境
- 创建 veth 接口、Bridge 虚拟交换机、vtep 接口
- 验证 l2miss 和 l3miss 通知事件
- 配置路由
- 验证连通性,Guest0 ping Guest1
准备环境
网口配置如下:
# Host0
[root@i-7dlclo08 ~]# ip -d a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:ca:9d:db:ff brd ff:ff:ff:ff:ff:ff promiscuity 0
inet 192.168.100.2/24 brd 192.168.100.255 scope global dynamic eth0
valid_lft 24182sec preferred_lft 24182sec
inet6 fe80::76ef:824d:95ef:18a3/64 scope link
valid_lft forever preferred_lft forever
48: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP qlen 1000
link/ether 5a:5f:4f:3c:4d:a6 brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge forward_delay 1500 hello_time 200 max_age 2000
inet 10.20.1.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::585f:4fff:fe3c:4da6/64 scope link
valid_lft forever preferred_lft forever
50: veth0@if49: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether 82:17:03:c5:a5:bf brd ff:ff:ff:ff:ff:ff link-netnsid 1 promiscuity 1
veth
bridge_slave
inet6 fe80::8017:3ff:fec5:a5bf/64 scope link
valid_lft forever preferred_lft forever
51: vtep0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN qlen 1000
link/ether 52:2d:1f:cb:13:55 brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 1 dev eth0 srcport 0 0 dstport 4789 nolearning proxy l2miss l3miss ageing 300
bridge_slave
# Host1
[root@i-hh5ai710 ~]# ip -d a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:d5:9b:94:4c brd ff:ff:ff:ff:ff:ff promiscuity 0
inet 192.168.100.3/24 brd 192.168.100.255 scope global dynamic eth0
valid_lft 30286sec preferred_lft 30286sec
inet6 fe80::baef:a34c:3194:d36e/64 scope link
valid_lft forever preferred_lft forever
87: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP qlen 1000
link/ether d6:ca:34:af:d7:fd brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge forward_delay 1500 hello_time 200 max_age 2000
inet 10.20.1.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::d4ca:34ff:feaf:d7fd/64 scope link
valid_lft forever preferred_lft forever
89: veth0@if88: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether 42:3b:18:50:10:d6 brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
veth
bridge_slave
inet6 fe80::403b:18ff:fe50:10d6/64 scope link
valid_lft forever preferred_lft forever
90: vtep0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN qlen 1000
link/ether 52:2f:17:7c:bc:0f brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 1 dev eth0 srcport 0 0 dstport 4789 nolearning proxy l2miss l3miss ageing 300
bridge_slave
观察 l2miss 和 l3miss 通知事件
# Host0 10.20.1.4 ping 10.20.1.3
[root@i-7dlclo08 ~]# ip netns exec ns0 ping 10.20.1.3
PING 10.20.1.3 (10.20.1.3) 56(84) bytes of data.
From 10.20.1.4 icmp_seq=1 Destination Host Unreachable
# See l2miss & l3miss
[root@i-7dlclo08 ~]# ip monitor all
[nsid current]miss 10.20.1.3 dev vtep0 STALE
[nsid 1]10.20.1.3 dev if49 FAILED
当缺失 ARP 记录时触发[nsid 1]10.20.1.3 dev if45 FAILED,当缺失 FDB 转发记录时触发[nsid current]miss dev vtep0 lladdr e6:4b:f9:ce:d7:7b STALE,与预期一样,未配置路由前,网络不通。
配置 Guest 的转发表和路由表
[root@i-7dlclo08 ~]# ip n add 10.20.1.3 lladdr e6:4b:f9:ce:d7:7b dev vtep0
[root@i-7dlclo08 ~]# bridge fdb add e6:4b:f9:ce:d7:7b dst 192.168.100.3 dev vtep0
[root@i-7dlclo08 ~]# ip r add 10.20.0.0/16 dev vtep0 scope link via 10.20.1.0
回程路由类似。
测试连通性
10.20.1.4 ping 10.20.1.3
[root@i-7dlclo08 ~]# ip netns exec ns0 ping 10.20.1.3
PING 10.20.1.3 (10.20.1.3) 56(84) bytes of data.
64 bytes from 10.20.1.3: icmp_seq=1 ttl=64 time=1.04 ms
64 bytes from 10.20.1.3: icmp_seq=2 ttl=64 time=0.438 ms
配置好对端 Guest 路由后,网络连通成功。通过成功配置需要互通所有 Guest 路由转发信息后,Overlay 的数据包能成功抵达最终目的 Host 的目的 Guest 接口上。
l2miss 和 l3miss 方案缺陷
- 每一台 Host 需要配置所有需要互通 Guest MAC 地址,ARP 和 FDB 记录会膨胀,不适合海量 Container 场景
- 对 kernel DOVE 机制有依赖,且首次一定失败,要通过 miss 消息通知而学习规则
三层路由 vxlan 实现方案
为了弥补 l2miss 和 l3miss 的缺陷,flannel 改用了更普遍的三层路由的实现方案。
理论基础
组网:
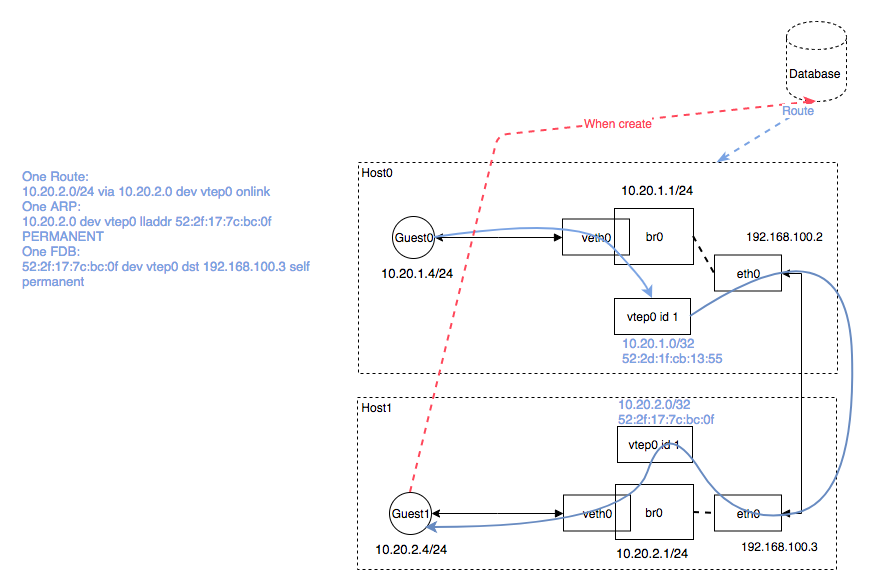
Flannel 在最新 vxlan 实现上完全去掉了 l2miss & l3miss 方式,Flannel deamon 不再监听 netlink 通知,因此也不依赖 DOVE。而改成给每一台 Node 分配独自的 subnet 子网地址(通过 docker 的 –bip 参数分配 br0 上的 subnet range),所有送往这个子网的数据包都在其他 Node 上主动配置路由信息,相当于原来通过 MAC 寻址的方式,现在按照 DST IP 归属哪个 subnet 就送达到固定的 Node 上,这样的好处就是 Host 不需要配置所有的 Guest 二层 MAC 地址,从一个二层寻址转换成三层寻址,路由数目与 Host 机器数呈线性相关,做到了同一个 VNI 下每一台 Host 主机 1 route,1 arp entry and 1 FDB entry。
流程如下:
- Host0 中 flanneld 启动时候为 Host0 注册
10.20.1.0/24子网,同时添加10.20.2.0/24的路由在 host0 中,host1 同理。 - 配置 ARP 记录
10.20.2.0范围的地址的 MAC 地址为 Host1 中 vtep 地址52:2f:17:7c:bc:0f - 配置 br0 中 FDB 表发送给
52:2f:17:7c:bc:0f的数据包走vtep0出,目的为192.168.100.3 - Guest0 访问
10.20.2.4时发现为三层寻址,则通过 host 路由匹配通过 host0 的 vtep 网卡出去 - Host0 开始寻找
10.20.2.0的 MAC 地址,匹配 ARP 记录52:2f:17:7c:bc:0f - 匹配 FDB 表中
52:2f:17:7c:bc:0f记录开始走 host0 的 vtep0 封装出去 - 数据包达到 Host1 后,解包匹配 br0 的
10.20.2.0/24路由把数据包传递给 br0,最终通过二层 MAC 寻址找到 Container
模拟验证
环境:
- 2 台 Centos7.x 机器,2张网卡
- 2 个 Bridge,2 张 vtep 网卡
- 2 个 Namespace,2 对 veth 接口
步骤:
- 创建 Namespace 网络隔离空间模拟 Guest 环境
- 创建 veth 接口、Bridge 虚拟交换机、vtep 接口
- 配置路由
- 验证连通性,Guest0 ping Guest1
准备环境
网口配置如下:
# Host0 网络配置接口
[root@i-7dlclo08 ~]# ip -d a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:ca:9d:db:ff brd ff:ff:ff:ff:ff:ff promiscuity 0
inet 192.168.100.2/24 brd 192.168.100.255 scope global dynamic eth0
valid_lft 43081sec preferred_lft 43081sec
inet6 fe80::76ef:824d:95ef:18a3/64 scope link
valid_lft forever preferred_lft forever
60: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 5a:5f:4f:3c:4d:a6 brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge forward_delay 1500 hello_time 200 max_age 2000
inet 10.20.1.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::585f:4fff:fe3c:4da6/64 scope link
valid_lft forever preferred_lft forever
62: veth0@if61: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether 92:6d:63:de:28:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1 promiscuity 1
veth
bridge_slave
inet6 fe80::906d:63ff:fede:28d2/64 scope link
valid_lft forever preferred_lft forever
63: vtep0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN qlen 1000
link/ether 52:2d:1f:cb:13:55 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 dev eth0 srcport 0 0 dstport 4789 nolearning proxy l2miss l3miss ageing 300
inet 10.20.1.0/32 scope global vtep0
valid_lft forever preferred_lft forever
# Host1 网络配置接口
[root@i-hh5ai710 ~]# ip -d a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:d5:9b:94:4c brd ff:ff:ff:ff:ff:ff promiscuity 0
inet 192.168.100.3/24 brd 192.168.100.255 scope global dynamic eth0
valid_lft 29412sec preferred_lft 29412sec
inet6 fe80::baef:a34c:3194:d36e/64 scope link
valid_lft forever preferred_lft forever
95: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether d6:ca:34:af:d7:fd brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge forward_delay 1500 hello_time 200 max_age 2000
inet 10.20.2.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::d4ca:34ff:feaf:d7fd/64 scope link
valid_lft forever preferred_lft forever
97: veth0@if96: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether a6:cc:5b:a4:54:d3 brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
veth
bridge_slave
inet6 fe80::a4cc:5bff:fea4:54d3/64 scope link
valid_lft forever preferred_lft forever
98: vtep0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN qlen 1000
link/ether 52:2f:17:7c:bc:0f brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 dev eth0 srcport 0 0 dstport 4789 nolearning proxy l2miss l3miss ageing 300
inet 10.20.2.0/32 scope global vtep0
valid_lft forever preferred_lft forever
路由 Host 配置
# One Route
10.20.2.0/24 via 10.20.2.0 dev vtep0 onlink
# One ARP
10.20.2.0 dev vtep0 lladdr 52:2f:17:7c:bc:0f PERMANENT
# One FDB
52:2f:17:7c:bc:0f dev vtep0 dst 192.168.100.3 self permanent
回程路由类似。
测试连通性
10.20.1.4 ping 10.20.2.4
[root@i-7dlclo08 ~]# ip netns exec ns0 ping 10.20.2.4
PING 10.20.2.4 (10.20.2.4) 56(84) bytes of data.
64 bytes from 10.20.2.4: icmp_seq=1 ttl=62 time=0.992 ms
64 bytes from 10.20.2.4: icmp_seq=2 ttl=62 time=0.518 ms
可以看到,通过增加一条三层路由 10.20.2.0/24 via 10.20.2.0 dev vtep0 onlink 使目标匹配 10.20.2.0/24 的目的 IP 包通过 vtep0 接口送往目的 Host1,目的 Host1 收到后,在本地 Host 做转发,最终送往 veth0 接口。在 Host 多个 Guest 场景下也无需额外配置 Guest 路由,从而减少路由数量,方法变得高效。
总结
可以看到 SDN 的 Overlay 配置很灵活也很巧妙,Overlay 的数据包通过 vxlan 这种隧道技术穿透 Underlay 网络,路由配置很灵活,不管多么灵活,最终还是基于网络中的二三层路由转发的基本原则。
其他
分析了 vxlan 的基本原理后,flannel 还主要支持 hostgw、udp 的实现。
Host-gw 模式
Host-gw 的基本原理比较简单,是直接在 host 主机上配置 Overlay 的 subnet 对端 host 的路由信息,数据包没有经过任何封装而直接送往对端,这就要求 Host 在同一个二层网络中,因为没有 vetp 做封装,也意味着 Underlay 的安全策略需要和 Overlay 一致。这种模式也不需要任何额外的虚拟网络设备,数据包直接通过 eth0 进出,因为简单也是效率最高的,与 calico 的方案有点类似。 整个后端核心代码量在 50 行左右,如下:
package hostgw
func (be *HostgwBackend) RegisterNetwork(ctx context.Context, wg sync.WaitGroup, config *subnet.Config) (backend.Network, error) {
n := &backend.RouteNetwork{
SimpleNetwork: backend.SimpleNetwork{
ExtIface: be.extIface,
},
SM: be.sm,
BackendType: "host-gw",
Mtu: be.extIface.Iface.MTU,
LinkIndex: be.extIface.Iface.Index,
}
n.GetRoute = func(lease *subnet.Lease) *netlink.Route {
return &netlink.Route{
Dst: lease.Subnet.ToIPNet(), // 目的地址路由,如 10.20.1.0/24
Gw: lease.Attrs.PublicIP.ToIP(), // Underlay Dst Host IP 192.168.100.3
LinkIndex: n.LinkIndex,
}
}
attrs := subnet.LeaseAttrs{
PublicIP: ip.FromIP(be.extIface.ExtAddr),
BackendType: "host-gw",
}
l, err := be.sm.AcquireLease(ctx, &attrs)
switch err {
case nil:
n.SubnetLease = l
case context.Canceled, context.DeadlineExceeded:
return nil, err
default:
return nil, fmt.Errorf("failed to acquire lease: %v", err)
}
return n, nil
}
可以看到添加 subnet 给 dst,同时添加 host 的 publicIP 给 gw,主要对 host 直接进行路由操作。
模拟组网:
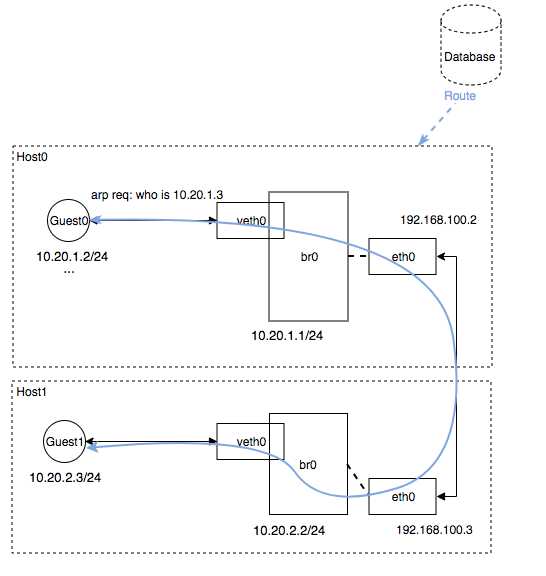
模拟验证:
# HOST0
[root@i-7dlclo08 ~]# ip r
default via 192.168.100.1 dev eth0 proto static metric 100
10.20.1.0/24 dev br0 proto kernel scope link src 10.20.1.1
10.20.2.0/24 via 192.168.100.3 dev eth0
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.2 metric 100
# HOST1
[root@i-hh5ai710 ~]# ip r
default via 192.168.100.1 dev eth0 proto static metric 100
10.20.1.0/24 via 192.168.100.2 dev eth0
10.20.2.0/24 dev br0 proto kernel scope link src 10.20.2.1
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.3 metric 100
# Guest0 ping Guest1
[root@i-7dlclo08 ~]# ip netns exec ns0 ping 10.20.2.2
PING 10.20.2.2 (10.20.2.2) 56(84) bytes of data.
64 bytes from 10.20.2.2: icmp_seq=1 ttl=62 time=1.29 ms
64 bytes from 10.20.2.2: icmp_seq=2 ttl=62 time=0.868 ms
UDP 模式
UDP 模式和 vxlan 类似是一种隧道实现,即为 host 创建一个 tun 的设备,tun 设备是一个虚拟网路设备,通常一端连接着 kernel 网络协议栈,而另一端就取决于网络设备驱动的实现,一般连接着应用进程,网络数据包发送到这个 tun 设备上后从管道的出口到达应用程序,这个时候应用程序可以根据需求对数据包进行拆包和解包再回传给 eth0 或其他网络设备,从而到达隧道的另一端。 而 flannel 的 udp 模式 tun 设备连接的另一端是 flanneld 进程,这里不单独部署验证。
模拟组网:
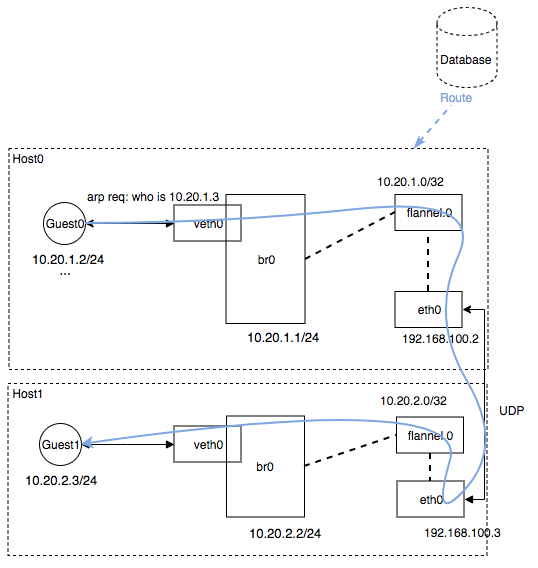
可以看到数据包传送给 flanneld 进程,然后由 flanneld 进行 UDP 拆包和封包移交给目的设备。
核心代码:
func configureIface(ifname string, ipn ip.IP4Net, mtu int) error {
iface, err := netlink.LinkByName(ifname)
if err != nil {
return fmt.Errorf("failed to lookup interface %v", ifname)
}
// Ensure that the device has a /32 address so that no broadcast routes are created.
// This IP is just used as a source address for host to workload traffic (so
// the return path for the traffic has an address on the flannel network to use as the destination)
ipnLocal := ipn
ipnLocal.PrefixLen = 32
err = netlink.AddrAdd(iface, &netlink.Addr{IPNet: ipnLocal.ToIPNet(), Label: ""})
if err != nil {
return fmt.Errorf("failed to add IP address %v to %v: %v", ipnLocal.String(), ifname, err)
}
err = netlink.LinkSetMTU(iface, mtu)
if err != nil {
return fmt.Errorf("failed to set MTU for %v: %v", ifname, err)
}
err = netlink.LinkSetUp(iface)
if err != nil {
return fmt.Errorf("failed to set interface %v to UP state: %v", ifname, err)
}
// explicitly add a route since there might be a route for a subnet already
// installed by Docker and then it won't get auto added
err = netlink.RouteAdd(&netlink.Route{
LinkIndex: iface.Attrs().Index,
Scope: netlink.SCOPE_UNIVERSE,
Dst: ipn.Network().ToIPNet(),
})
if err != nil && err != syscall.EEXIST {
return fmt.Errorf("failed to add route (%v -> %v): %v", ipn.Network().String(), ifname, err)
}
return nil
}
func (n *network) processSubnetEvents(batch []subnet.Event) {
for _, evt := range batch {
switch evt.Type {
case subnet.EventAdded:
log.Info("Subnet added: ", evt.Lease.Subnet)
setRoute(n.ctl, evt.Lease.Subnet, evt.Lease.Attrs.PublicIP, n.port)
case subnet.EventRemoved:
log.Info("Subnet removed: ", evt.Lease.Subnet)
removeRoute(n.ctl, evt.Lease.Subnet)
default:
log.Error("Internal error: unknown event type: ", int(evt.Type))
}
}
}
这里 flannel.0 的设备通过 iface, err := netlink.LinkByName(ifname) 获取,配置 ip 地址和路由,整体方案与 vxlan 类似,但性能和稳定性比 vxlan 要差,并不被官方推荐使用。