背景和想法
Service Mesh 提供了微服务化开发的新思路,核心思想是构建一个代理转发网络并结合控制和转发分离的做法来对成千上万个微服务间做流量、策略、安全等管理,而另一方面 Linux Kernel 提供一种运行时高效扩可编程的网络注入机制 eBPF,借此能实现 L47 层代理转发。假设借助 eBPF,作为 Service Mesh 的数据转发层,对接 Pilot、Mixer 等控制面,实现策略、流量和安全管理,是不是一种更高效的方式?这会比 Envoy 拥有更好的性能,虽然性能未必是 Mesh 首要考虑的问题,后搜索发现 Cilium 果然做了类似的尝试,详情见 http://docs.cilium.io/en/latest/gettingstarted/istio/,但对接的方式很特别,并不像 Envoy 一样,为每一个 Pod 部署一个 Envoy 容器,而是在多个 Pod 外部署一个 Cilium,以 Kubernetes Daemon Set 模式部署,为多个 Pod 进行代理,对控制器层面的 Pilot 做了定制,部署配置如下:
$ sed -e 's,docker\.io/istio/pilot:,docker.io/cilium/istio_pilot:,' \
< ${ISTIO_HOME}/install/kubernetes/istio.yaml | \
kubectl create -f -
Cilium 部署了一个“书店”集群服务为例子来说明,如下,在下发“路由策略”之前流量如下:
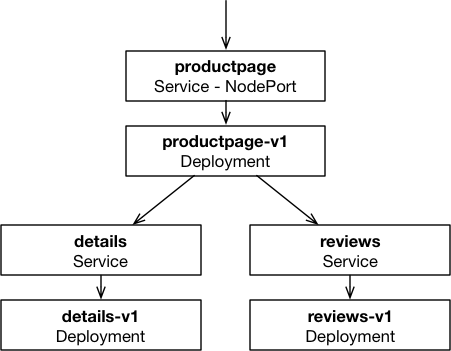 正常流量从书页到详情页,到评论页面
正常流量从书页到详情页,到评论页面
配置一条 istio 路由策略,把流量全部导向 reviews-v1,reviews-v2 没有流量
apiVersion: config.istio.io/v1alpha2
kind: RouteRule
metadata:
name: reviews-default
spec:
destination:
name: reviews
precedence: 1
route:
- labels:
version: v1
导流后如下:
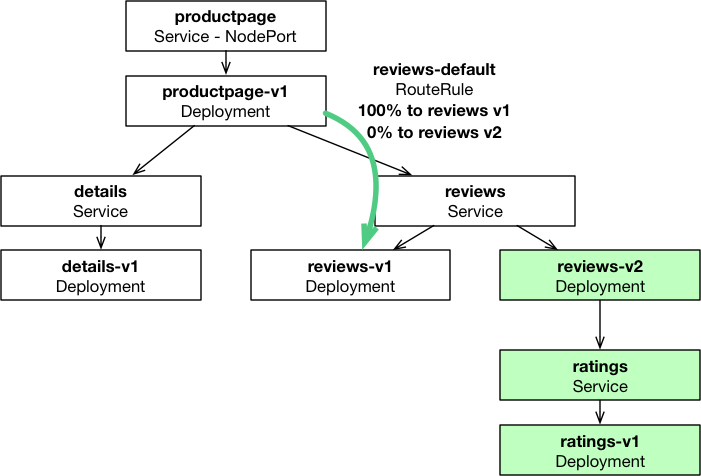
可见,Cilium 能识别 service-name 和 labels ,并进行导流。策略相当灵活。
Cilium 还做了个性能测试,在 Pod - Proxy - Pod 场景下的请求延迟对比:
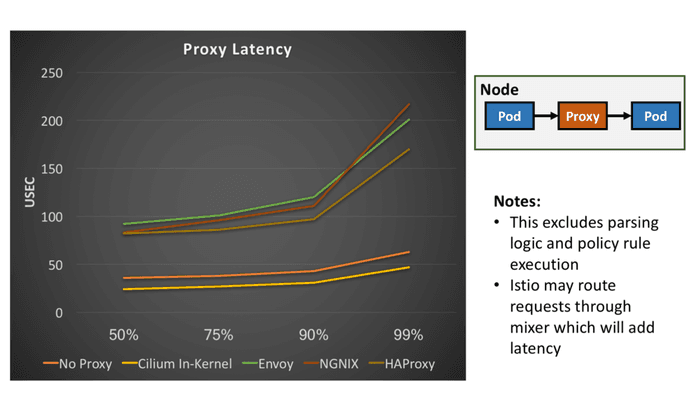
Cilium 的延迟全部小于当前的 Envoy、Nginx、Haproxy 代理。
从服务化 SpringCloud 框架开始
我比较赞同微服务是一种 SOA 的衍生形态的观点,微服务并不完全是一种新的东西。SpringCloud 就是一种微服务化应用框架,目的在于帮助应用快速进行微服务化开发,官方定位如下:
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems (e.g. configuration management, service discovery, circuit breakers, intelligent routing, micro-proxy, control bus, one-time tokens, global locks, leadership election, distributed sessions, cluster state). Coordination of distributed systems leads to boiler plate patterns, and using Spring Cloud developers can quickly stand up services and applications that implement those patterns.
提供了微服务所需的配置管理、服务发现、服务环路发现、智能路由、代理、全局锁、集群选主、分布式 Session、集群状态管理等基础能力。
新服务化转折点 Service Mesh
而 2016 年,两个不为人知的小项目 linked 和 Envoy 也许没有想到自己在两年后的今天承载了下一代微服务框架的使命:无侵入式微服务架构,这种架构目前有星星燎原之势取代 SpringCloud 模式成为转折点,新架构完全解耦微服务框架和应用,使应用节点不再关心服务注册、发现、调用等问题,应用只管把请求发送给与应用共部署的代理进程,这个代理进程对内外承接应用所有的请求,并自身组成一个网络,相互间调用,最终把请求返回给应用,这意味着应用只关心自身业务实现,不再关心请求是如何发送的,发送到哪里的,统一由代理进程进行转发。并且应用代码可以用任何语言实现,在代码层面和框架完全解耦,不像 SpringCloud 应用进程需要基于这个框架进行开发,而是彻底地从应用进程中分离,这种解耦似乎一下子使整体系统的复杂度下降了一个级别。框架从应用代码中完全下沉到了另一个代理进程中,应用和“代理”仅以标准的协议交互,换句话说,框架从函数级别的接口变成了进程间通讯接口。这种彻底的解耦让应用抛开“包袱”变得轻量,这在复杂系统和资源敏感型系统中非常有好处,比如应用可以使用相比 Java 占用资源的 golang 语言编写程序;比如改变业务代码更加容易,也不会因为框架改变导致业务代码改变。进而不妨再大胆想象一下,曾经我们使用的 database library 是否也可以从应用代码里剥离出来下沉到代理进程呢?
2016年9月,Linked 背后的创业公司 Buoyant 第一次在 SF Microservices 提出了“Service Mesh” 概念,并随后在 2017 年 4月 William Morgan 给 Service Mesh 做了定义:
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
are deployed alongside application code, without the application needing to be aware 这句话道出了 mesh 的核心,即对应用无感知和无侵入。微服务框架从应用代码里剥离出来,从强依赖变成弱依赖,甚至无依赖,应用本身不再关心集群状态、调用路由、安全策略等等,甚至可以自由升级,框架升级不再影响应用自身,业务迭代变得更加迅速,解耦带来了巨大收益,架构变得更加优雅。
Service Mesh 的两个核心组件为控制组件和数据组件,数据组件和应用一起部署,接管应用所有请求,应用只需访问类似 http://127.0.0.1/service 地址,剩下代理进程会转发请求到对应的对端服务,并实现服务发现注册、流量控制、安全控制等功能。所有代理进程相互连通,组成了像一个格子的网络,并整个网络被一个控制器管理,而这个网格就叫做 Mesh 。Service Mesh 的数据层组件的主要实现者是 Linked 和 Envoy。
2017年5月24日,Google 和 IBM 高调发布了基于 Service Mesh 思想的服务化框架产品 Istio,出身名门的 Istio 一下子火了,并给当时出身草根的 Linked 产品承重一击,Linked 瞬间陷入了黑暗。Istio 数据层收编了 Envoy ,自己做了控制层,提供 Pilot、Mixer、Istio-Auth 三大组件,如下:
- Mixer:提供监控数据管理、路由、负载均衡、路由、调用追踪等流量管理,是控制器的核心,并提供后端对接平台,如k8s、Mesos等。
- Pilot(飞行员): Mixer 的执行模块,负责对 Envoy 进行运行时配置。
- Istio-Auth:提供服务间 TLS 安全通信、角色鉴权、用户认证等 AAA 管理。
Envoy 与应用部署在一起,提供服务间请求高效转发,并提供扩展接口以实现不同的转发策略,同时上报流量监控数据,提供 HTTP、gRPC、TCP 转发能力。

一开始 Linked 仅仅只有数据层面,是缺乏控制面的,而 Istio 一开始的定位就很清晰地包括了控制和数据面,后来 Buoyant 公司借鉴 Istio 的思想,开发了与 Istio 竞争的 Conduit,控制面用 Rust 开发,从这个角度讲, Google 似乎看得更远,Buoyant 挺有危机感。
介绍完 Service Mesh,来看看能实现一个类似数据转发层的 eBPF 框架。
新内核的网络利器 eBPF
eBPF(Extended Berkeley Packet Filter)是 Kernel 3.18 之后的一个内核模块,提供了一种在网络栈的钩子节点处动态运行用户代码的能力,这种动态加载无需重启 Kernel ,用户使用 C 语言编写,由 llvm 编译成可执行文件,但因为是在内核态执行,eBPF 对用户代码非常严格,甚至提供了一个叫 verifier 的审核模块对用户代码进行检查,确保用户代码符合内核要求,并同时能在短时间内执行完毕,即便如此,只要设计巧妙,也能实现很高级的网络功能,Cilium 的能力和价值就在此了。
编写 eBPF 的限制如下:
- 在 Kernel 4.16 和 LLVM 6.0 之前不支持普通函数调用,所有调用必须为内联函数
- 最大只能执行 4096 个 BPF 指令
- 不支持共享库调用(使用 bfp/lib 定义的库)
- 不允许全局变量,但可以使用
BPF_MAP_TYPE_PERCPU_ARRAY作为全局 map 存储状态信息,并可以在多个 BPF 程序间共享数据 - 不允许使用字符串常量和数组
- 限制性的使用循环,BPF verifier 验证程序会检测代码是否有循环,使用
#pragma unroll和BPF_MAP_TYPE_PERCPU_ARRAY最大只能支持 32 次迭代 - 栈空间限制大小 512 bytes
为了编写方便,内核也提供一些可以使用的组件如下:
- Helper Func:提供一些从内核中读写数据流的函数集
- Maps:内核中存储 KV 的 Map 集,用于变相存储全局变量
- Tail Calls 和 BPF to BPF Calls:BPF 程序调用另一个 BPF 程序,这样就能使功能模块化了
其他能力:
- JIT:即时翻译执行代码能力
- Offloads:允许用户代码下沉到网卡中执行
总之,要编写一个高级 BPF 相对普通开发还是有难度的,下面介绍个简单的例子,主要实现对网卡上下行进出流量进行统计。
-
开发环境准备
当前 Ubuntu 17.04 以上版本,按照编译所依赖的包
$ sudo apt-get install -y make gcc libssl-dev bc libelf-dev libcap-dev \ clang gcc-multilib llvm libncurses5-dev git pkg-config libmnl bison flex \ graphviz -
编码代码 tc-example.c 实现对进出流量传输字节进行计数
#include <linux/bpf.h> #include <linux/pkt_cls.h> #include <stdint.h> #include <iproute2/bpf_elf.h> #ifndef __section # define __section(NAME) \ __attribute__((section(NAME), used)) #endif #ifndef __inline # define __inline \ inline __attribute__((always_inline)) #endif #ifndef lock_xadd # define lock_xadd(ptr, val) \ ((void)__sync_fetch_and_add(ptr, val)) #endif #ifndef BPF_FUNC # define BPF_FUNC(NAME, ...) \ (*NAME)(__VA_ARGS__) = (void *)BPF_FUNC_##NAME #endif static void *BPF_FUNC(map_lookup_elem, void *map, const void *key); struct bpf_elf_map acc_map __section("maps") = { .type = BPF_MAP_TYPE_ARRAY, .size_key = sizeof(uint32_t), .size_value = sizeof(uint32_t), .pinning = PIN_GLOBAL_NS, .max_elem = 2, }; static __inline int account_data(struct __sk_buff *skb, uint32_t dir) { uint32_t *bytes; bytes = map_lookup_elem(&acc_map, &dir); if (bytes) lock_xadd(bytes, skb->len); return TC_ACT_OK; } __section("ingress") int tc_ingress(struct __sk_buff *skb) { return account_data(skb, 0); } __section("egress") int tc_egress(struct __sk_buff *skb) { return account_data(skb, 1); } char __license[] __section("license") = "GPL"; /** * struct sk_buff - socket buffer, it's the primary struct for network. * See https://elixir.bootlin.com/linux/latest/source/include/linux/skbuff.h) * @next: Next buffer in list * @prev: Previous buffer in list * @tstamp: Time we arrived/left * @rbnode: RB tree node, alternative to next/prev for netem/tcp * @sk: Socket we are owned by * @dev: Device we arrived on/are leaving by * @cb: Control buffer. Free for use by every layer. Put private vars here * @_skb_refdst: destination entry (with norefcount bit) * @sp: the security path, used for xfrm * @len: Length of actual data * @data_len: Data length * @mac_len: Length of link layer header * @hdr_len: writable header length of cloned skb * @csum: Checksum (must include start/offset pair) * @csum_start: Offset from skb->head where checksumming should start * @csum_offset: Offset from csum_start where checksum should be stored * @priority: Packet queueing priority * @ignore_df: allow local fragmentation * @cloned: Head may be cloned (check refcnt to be sure) * @ip_summed: Driver fed us an IP checksum * @nohdr: Payload reference only, must not modify header * @pkt_type: Packet class * @fclone: skbuff clone status * @ipvs_property: skbuff is owned by ipvs * @tc_skip_classify: do not classify packet. set by IFB device * @tc_at_ingress: used within tc_classify to distinguish in/egress * @tc_redirected: packet was redirected by a tc action * @tc_from_ingress: if tc_redirected, tc_at_ingress at time of redirect * @peeked: this packet has been seen already, so stats have been * done for it, don't do them again * @nf_trace: netfilter packet trace flag * @protocol: Packet protocol from driver * @destructor: Destruct function * @tcp_tsorted_anchor: list structure for TCP (tp->tsorted_sent_queue) * @_nfct: Associated connection, if any (with nfctinfo bits) * @nf_bridge: Saved data about a bridged frame - see br_netfilter.c * @skb_iif: ifindex of device we arrived on * @tc_index: Traffic control index * @hash: the packet hash * @queue_mapping: Queue mapping for multiqueue devices * @xmit_more: More SKBs are pending for this queue * @ndisc_nodetype: router type (from link layer) * @ooo_okay: allow the mapping of a socket to a queue to be changed * @l4_hash: indicate hash is a canonical 4-tuple hash over transport * ports. * @sw_hash: indicates hash was computed in software stack * @wifi_acked_valid: wifi_acked was set * @wifi_acked: whether frame was acked on wifi or not * @no_fcs: Request NIC to treat last 4 bytes as Ethernet FCS * @csum_not_inet: use CRC32c to resolve CHECKSUM_PARTIAL * @dst_pending_confirm: need to confirm neighbour * @napi_id: id of the NAPI struct this skb came from * @secmark: security marking * @mark: Generic packet mark * @vlan_proto: vlan encapsulation protocol * @vlan_tci: vlan tag control information * @inner_protocol: Protocol (encapsulation) * @inner_transport_header: Inner transport layer header (encapsulation) * @inner_network_header: Network layer header (encapsulation) * @inner_mac_header: Link layer header (encapsulation) * @transport_header: Transport layer header * @network_header: Network layer header * @mac_header: Link layer header * @tail: Tail pointer * @end: End pointer * @head: Head of buffer * @data: Data head pointer * @truesize: Buffer size * @users: User count - see {datagram,tcp}.c */ -
编译成 BPF 可执行程序
$ clang -O2 -Wall -target bpf -c tc-example.c -o tc-example.o -
加载执行程序到网卡
# tc qdisc add dev em1 clsact # tc filter add dev em1 ingress bpf da obj tc-example.o sec ingress # tc filter add dev em1 egress bpf da obj tc-example.o sec egress # tc filter show dev em1 ingress filter protocol all pref 49152 bpf filter protocol all pref 49152 bpf handle 0x1 tc-example.o:[ingress] direct-action id 1 tag c5f7825e5dac396f # tc filter show dev em1 egress filter protocol all pref 49152 bpf filter protocol all pref 49152 bpf handle 0x1 tc-example.o:[egress] direct-action id 2 tag b2fd5adc0f262714 # mount | grep bpf sysfs on /sys/fs/bpf type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel) bpf on /sys/fs/bpf type bpf (rw,relatime,mode=0700) # tree /sys/fs/bpf/ /sys/fs/bpf/ +-- ip -> /sys/fs/bpf/tc/ +-- tc | +-- globals | +-- acc_map +-- xdp -> /sys/fs/bpf/tc/ 4 directories, 1 file
以上展现了对当前网络数据包的操作,这种可编程的能力就给上层应用提供了无限的想象空间了,其中 Cilium 就是基于可编程 eBPF 之上开发了 L47 层网络管理框架。
为服务化诞生的 Cilium
Cilium 是一个强大的以 eBPF 为基础的网络框架,能做到 L47 层的安全策略、流量控制,并且性能高、灵活性强,主要解决微服务的使用场景,能与 kubernetes 集成,官方解释如下:
Cilium is open source software for transparently securing the network connectivity between application services deployed using Linux container management platforms like Docker and Kubernetes.
The development of modern datacenter applications has shifted to a service-oriented architecture often referred to as microservices, wherein a large application is split into small independent services that communicate with each other via APIs using lightweight protocols like HTTP.
Cilium 就定位为微服务解决网络管理问题。
Microservices applications tend to be highly dynamic, with individual containers getting started or destroyed as the application scales out / in to adapt to load changes and during rolling updates that are deployed as part of continuous delivery.
This shift toward highly dynamic microservices presents both a challenge and an opportunity in terms of securing connectivity between microservices.
要解决微服务架构下的网络问题的挑战和机会在于要适应微服务快速变化能力,因为微服务扩容和升级非常频繁,从而网络和安全管理也需要适应这种变革。
Traditional Linux network security approaches (e.g., iptables) filter on IP address and TCP/UDP ports, but IP addresses frequently churn in dynamic microservices environments. The highly volatile life cycle of containers causes these approaches to struggle to scale side by side with the application as load balancing tables and access control lists carrying hundreds of thousands of rules that need to be updated with a continuously growing frequency.
而使用传统的以 IP Base 的策略模型已经不再适应当今以微服务为模型的架构了,微服务的底层网络变化会非常灵活和迅速,如二层的网络 IP 地址可以迅速改变和销毁,传统安全策略如果基于 IP Policy 模型会产生成百上千条规则,并且这些规则会被频繁变更,变更的性能非常低下。
By leveraging Linux BPF, Cilium retains the ability to transparently insert security visibility + enforcement, but does so in a way that is based on service / pod / container identity (in contrast to IP address identification in traditional systems) and can filter on application-layer (e.g. HTTP). As a result, Cilium not only makes it simple to apply security policies in a highly dynamic environment by decoupling security from addressing, but can also provide stronger security isolation by operating at the HTTP-layer in addition to providing traditional Layer 3 and Layer 4 segmentation.
因此 Cilium 利用 BPF 的能力,能以 service / pod / container 为对象进行动态地网络和安全策略管理,解耦控制面的策略管理和不断变化的网络环境,还做到 7 层能力。
整体 Cilium 架构如下:
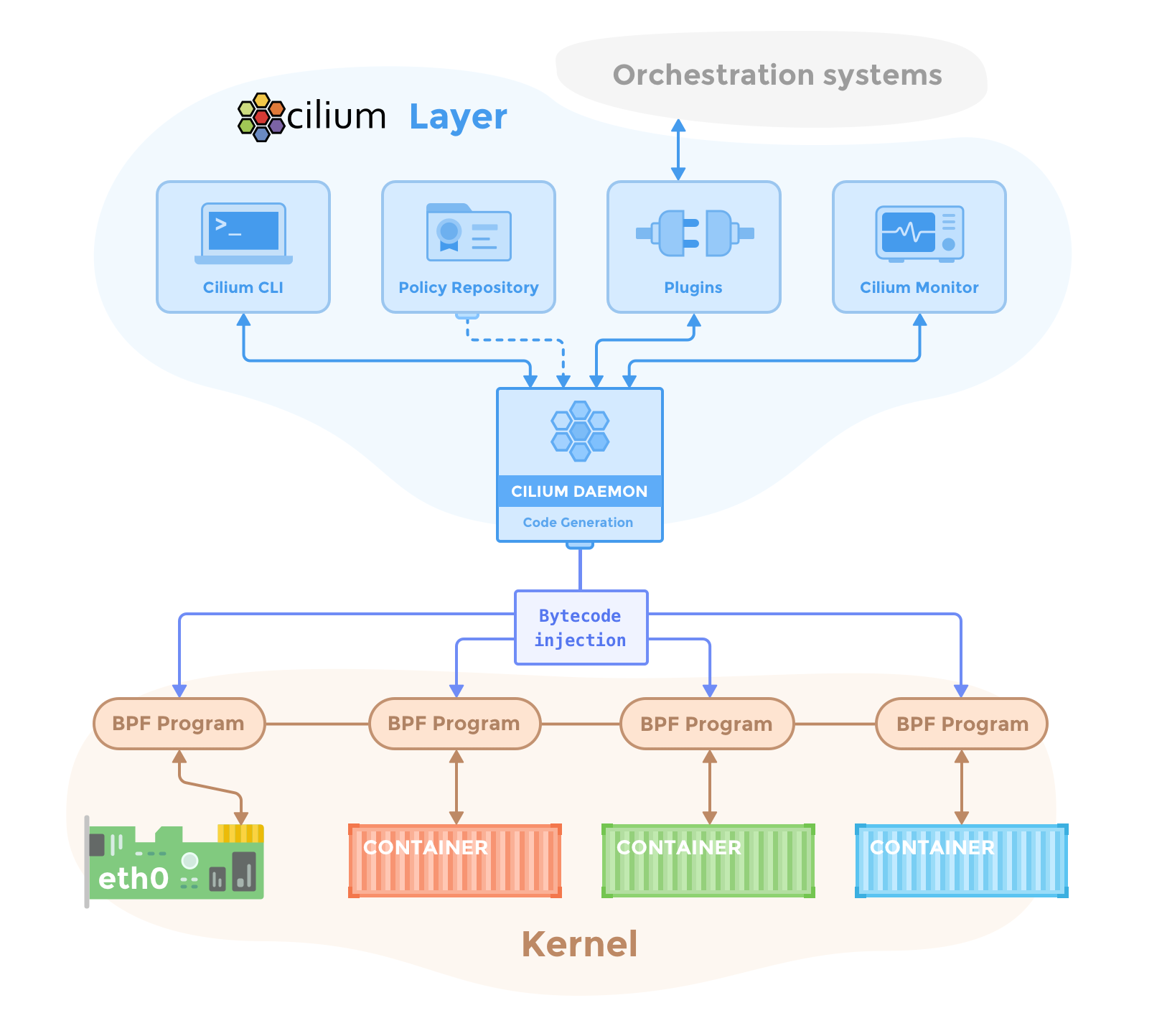
上层对接控制编排面,下层转换成 BPF 的程序注入到内核网络栈执行。
已实现的功能如下:
- 支持 HTTP 协议,支持 method、path、host、headers 匹配的策略
- 支持 Kafka 的协议,支持 Role、topic 匹配的策略管理
- 支持 IP/CIDR、Label、Service、Entities Base 的策略管理
- 负载均衡
- 监控和故障定位,支持对接 Prometheus 监控平台
可见 Cilium 做得很高级,不仅仅支持了 HTTP,还支持 Kafka 协议,相信未来还会支持更多的协议,提供更强大的功能,虽然看上去目前只能做到转发层业务(主要以网络栈 HOOK 的方式),对需要新建网络连接的业务有限制,但结合上层应用实现,做到替换 Envoy 数据层还是有可能的,尽情期待。